
This article was originally published on Synnada on August 16, 2023, and is part of our ongoing series on streaming SQL engines and advanced join algorithms. In previous posts, we discussed techniques like Probabilistic Data Structures in Streaming: Count-Min Sketch, General-purpose Stream Joins via Pruning Symmetric Hash Joins, and The Sliding Window Hash Join Algorithm that serve as building blocks. The concepts discussed in this series are implemented in Apache Arrow/DataFusion, which has a bunch of other cool features we haven’t talked about yet.
Most common use cases in time-series data involves windowing the data in some way or another. Many data processing frameworks and/or languages, including standard SQL, define windowing operators to support such use cases. Efficiently running such operators is an interesting (and surprisingly quite non-trivial) area of engineering, especially when we consider it as a milestone towards achieving the Kappa architecture — where one utilizes a unified compute engine that can handle both batch and streaming datasets.
In this blog post, we take a first step into this topic by analyzing the circumstances under which window queries can be run in streaming data applications without breaking the pipeline; i.e. in an on-line manner without breaking the stream. In other words, if we can calculate the window function results incrementally without scanning the entire input, we say that the window function is streamable or pipeline-friendly.
Background
Context: Streaming Query Execution
Before running a query, a query execution engine builds a physical plan that breaks down the query into a sequence of low-level executors/operators that compose together to compute what is described by the query. As the query runs, data flows between these operators and the engine incrementally builds/computes the final result in a pipelined fashion. If any of the executors/operators break the pipeline (meaning, it needs to see/scan all its input data before generating any result), the engine can not run the query in streaming/long-running use cases involving unbounded data sources. Therefore, our aim is to generate streaming-friendly physical plans whenever it is theoretically possible to do so. This blog post analyzes streaming execution support for window functions from this perspective.
Context: SQL Window Functions
A window function is a function that uses values from one or multiple rows to return a value for each row. The rows used by the window function to generate its results is determined by the window frame clause, which has the following syntax in SQL:
{ RANGE |ROWS |GROUPS } frame_start [ frame_exclusion ]
{ RANGE |ROWS |GROUPS } BETWEEN frame_start AND frame_end [ frame_exclusion ]where the prefix { RANGE | ROWS| GROUPS } determines the mode for specifying the window frame boundary. As an example, window frame ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING uses the previous row, the current row and the next row to calculate the result for every row; e.g. the 2nd row uses rows 1,2,3, the 3rd row uses rows 2,3,4 and so on.
Remark: For the purposes of this blog post, the window frame mode doesn’t make a difference. Therefore, we will use the ROWS mode in all of the examples henceforth.
Any data ordering requirement for the window function is specified by an optional ORDER BY clause. If we want to calculate the sum of last (let’s say, according to time) ten sales, we can use the following window expression in a SQL query:
SUM(sale) OVER(
ORDER BY ts ASC
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
)Finally, an optional PARTITION BY clause splits the input table into partitions (groups) based on the PARTITION BY expression. Window functions perform calculations for each such partition independently, allowing us to aggregate data within each partition separately. Effectively, a PARTITION BY clause divides the input table into multiple tables, each table containing the same PARTITION BY expression values. Then, the window expression sans the PARTITION BY clause is run on each “table” independently.
For example; if we were to calculate the sum of last (let’s say, according to time) ten sales for every country, we can use the following SQL query:
SELECT *, SUM(sale) OVER(
PARTITION BY country
ORDER BY ts ASC
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
)
FROM sales_tablewhere we chose to denote our input table with sales_table. If this table were to contain the following rows,
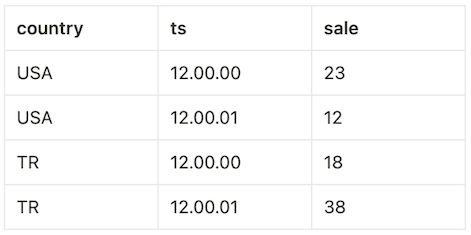
this query would work as if the input table were first split into mutually exclusive subsets, with each subset consisting of distinct country values, as follows:

Then, we would get a final result as if the following partitition-less query was executed for each partition separately:
SELECT *, SUM(sale) OVER(
ORDER BY ts ASC
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
)
FROM sales_tableRemark: For the purposes of this blog post, the exact window function in question (here, SUM) is not important. Therefore, we will use the SUM window function in all of the examples henceforth.
The final result would be the following table:
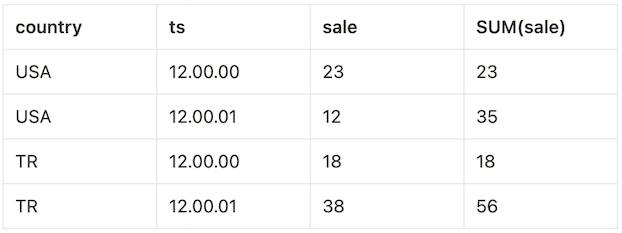
Typically; if a window query can generate its results incrementally as it scans its input, the output ordering of the window query will reflect the ordering of its input. However, this is not a strict requirement as long as implementations are concerned; a query execution engine may split table into multiple partitions and then merge these results without considering their original order [1]. Hence, the following result would also be valid:
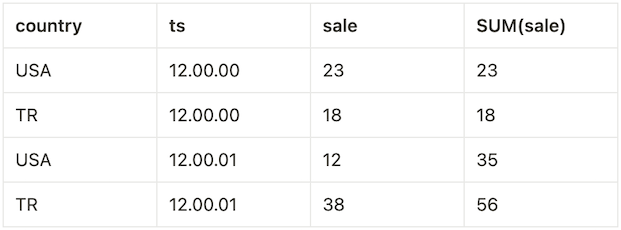
If one expects a specific output ordering for a window query, one should explicitly impose that ordering via a top-level ORDER BY clause.
Streaming Window Function Execution
In this section, we will analyze window specifications from the lens of streamability. In other words, we will analyze different kinds of window specifications and discuss whether it is possible to execute queries involving such windows without breaking the data processing pipeline.
In all of our examples, we will assume that the input of the windowing operator in question is a table named source. Schema and example data for the table source can be found below.
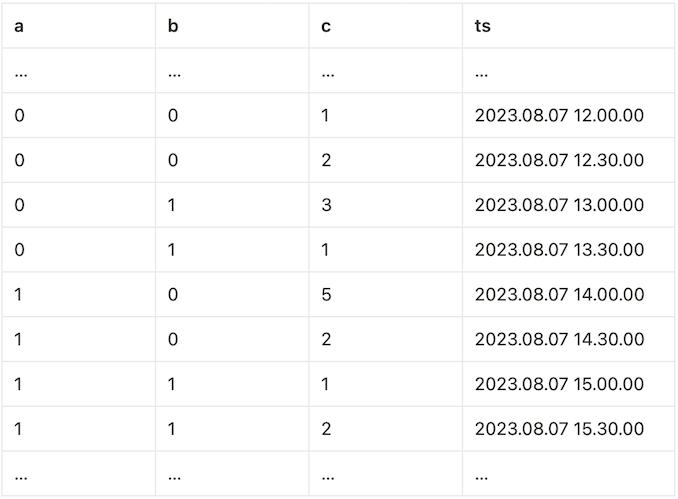
Furthermore, assume that the table source satisfies the ordering (ts ASC) as well as the ordering (a ASC, b ASC). Streaming support for window functions highly depends on data ordering, so this assumption will come into play multiple times during our analyses.
We will analyze the streamability of windowing operations under two main cases:
- When a window query doesn’t contain a
PARTITION BYclause in the specification, - When a window query contains a
PARTITION BYclause in the specification.
Case 1: Window specification doesn’t contain a PARTITION BY expression
In this case, we have window expressions of the following form:
function_name ( args ) **OVER** (
ORDER BY <expression> [<direction>] [, <expression> [<direction>] ...]
{ RANGE | ROWS | GROUPS } BETWEEN frame_start AND frame_end
)For a more in-depth syntactic specification as well as a general discussion of SQL window functions, see [2].
Consider the following expression as an example:
SUM(c) OVER (
ORDER BY ts ASC
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
)This windowing operation computes a sum value for each row in the table according to its window frame clause. The expression ORDER BY ts ASC describes the ordering requirement for this windowing operation. Naturally, the windowing operator will expect its input to satisfy the ordering requirement specified by this ORDER BY clause. Hence, for a window specification to be streamable, we have the following condition:
Under a non-composite ordering requirement (i.e. an ordering requirement involving a single expression), the input of the windowing operation should satisfy the ordering requirement as specified by the
ORDER BYclause. In our example, the input ordering should satisfyts ASC.
Next, let’s turn our attention to the window frame itself. The table below shows which rows are necessary to compute the sum value for each row in our table.

As can be seen from this table, our specific example lends itself to computing/finalizing the window function result for any given row whenever data for the subsequent row is received. This motivating example leads us to pose our next condition for streamability:
The window frame shouldn’t end with
UNBOUNDED FOLLOWING. When the frame ends withUNBOUNDED FOLLOWING, we need to see the whole data in order to compute/finalize our results.
Now, consider the case where more than one column/expression is used in the ORDER BY clause, such as the expression below:
SUM(c) OVER(
ORDER BY a ASC, c ASC
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
)This windowing operation expects its input to satisfy the ordering (a ASC, c ASC). However, remember that its input (i.e. table source) is ordered by (a ASC, b ASC). Does this mean all is lost? Thankfully, no — the windowing operator can actually buffer up rows until a new value of a is received and avoid breaking the pipeline. In our example, where we start with $a=0$, we would be buffering the following rows:
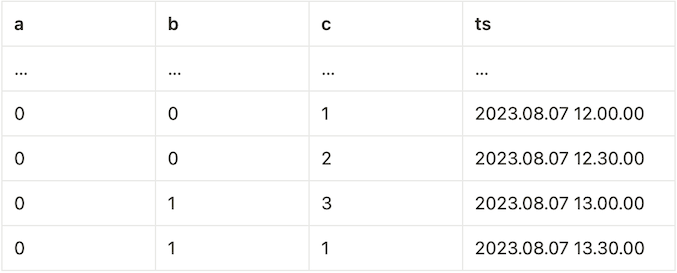
Then, we can sort this section according to the finer c ASC requirement, which turns the section above to following:
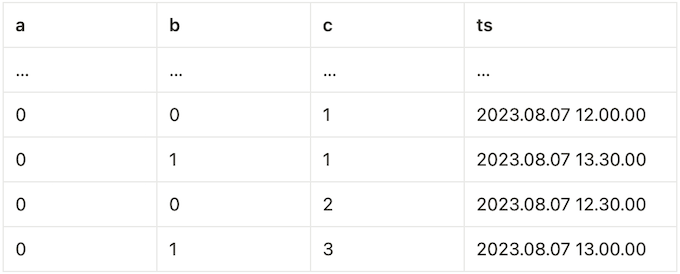
Now, window function results can be calculated using this new “sub-table”. Note that this algorithm effectively changes the input ordering of the windowing operator from (a ASC, b ASC) into (a ASC, c ASC). Note that this responsibility can be delegated to an external auxiliary operator, which itself would be streaming-friendly.
Generalizing our learnings, we can pose the following streamability condition for windowing operations with lexicographical ordering requirements:
The leading ordering requirement (the first ordering requirement) and the actual leading ordering (the first expression specifying the existing input ordering) should match [3].
Note that this condition is actually a generalization/relaxation of our first condition rather than a new, independent condition.
Summary
That’s it! We can now summarize our findings for the case we focused on: When a window query doesn’t have a PARTITION BY clause, streamability requires the following two conditions:
- The window frame shouldn’t end with
UNBOUNDED FOLLOWING. - The leading ordering requirement should match with the actual leading ordering of the input [3].
Remark: In analysis above, we stated that converting ordering (a ASC, b ASC) into ordering (a ASC, c ASC)is stream-friendly. This statement is only true as long as the common prefix between existing and required orderings (in our case a) isn’t the same for the entire stream, and changes frequently enough (in practice). Since we need to buffer data until we receive a new value for the common prefix; if this value never changes, we would need to scan/buffer the entire stream.
Case 2: Window specification contains a PARTITION BY expression
In this case, we have window expressions of the following form:
function_name ( args ) **OVER** (
PARTITION BY <expression> [, <expression> ...]
ORDER BY <expression> [<direction>] [, <expression> [<direction>] ...]
{ RANGE | ROWS | GROUPS } BETWEEN frame_start AND frame_end
)Let’s start our analysis through the following windowing operation:
SUM(c) OVER(
PARTITION BY a
ORDER BY b ASC
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
)For each partition, which consists of distinct a values, the window function will be calculated as if the operation were
SUM(c) OVER(
ORDER BY b ASC
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
)In our example, the table will be split into the partitions below:
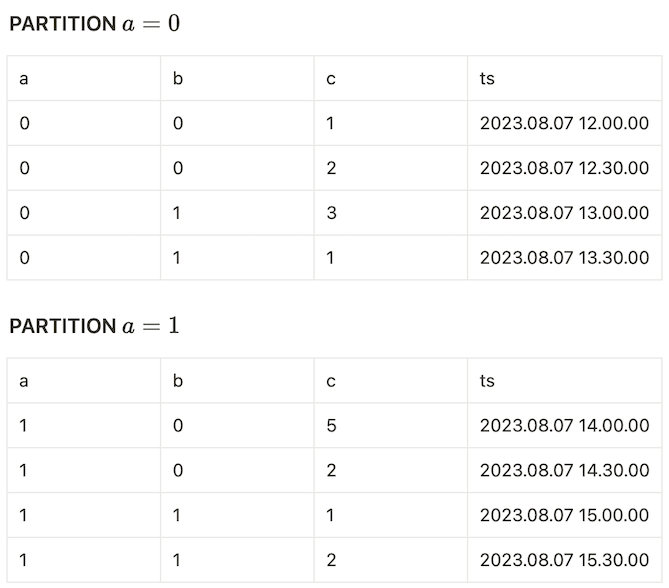
and so on.
The key requirement for supporting streaming execution for this windowing operation is the ability to somehow tell when a specific partition finalizes; as only then we can emit its associated results for window frames that “touch” the partition boundary.
Leveraging input data ordering for partitioning
Let’s first consider cases where the existing data (input) ordering helps us deal with partitions. In general; we can support streaming execution for a windowing operation involving partitions if the existing data ordering can be exploited to locate partition boundaries. We can formalize this observation as follows:
If the existing data (input) ordering satisfies the ordering associated with the expression(s) in the
PARTITION BYclause (in either direction for any of its constituent keys), then the windowing operation is streamable. For our example, the input should satisfy eithera ASC, ora DESC, or any lexicographical extension of these orderings.
Interestingly, we have even more flexibilities when we have composite partition keys. For example, consider the following window expression:
SUM(c) OVER(
PARTITION BY a, c
ORDER BY b ASC
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
)Here, each distinct (a, c) tuple would induce a partition. For our case, the partitions would be:
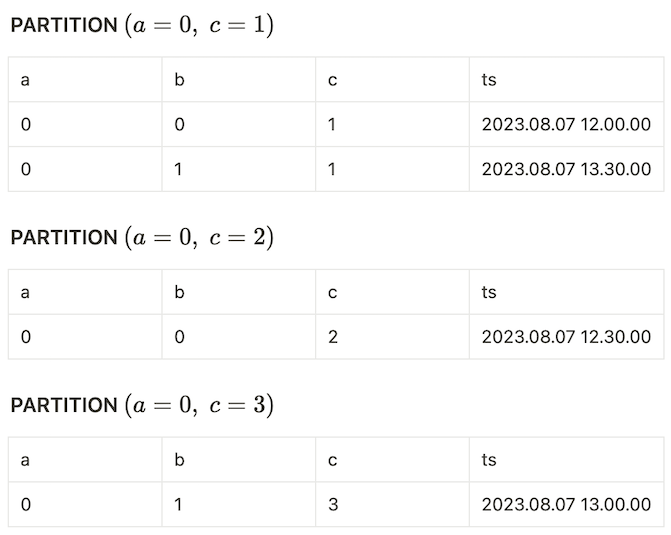
and so on.
In this example, the existing ordering (a ASC, b ASC) does not match perfectly with the keys of the PARTITION BY clause (a, c). However, they do share the prefix a. Can we still leverage this shared prefix? The answer is yes, because the clause PARTITION BY a, c describes a finer partitioning than the clause PARTITION BY a. Therefore; when we receive a new value of a = a_new after some a = a_last, we can be sure that any partition of the form (a = a_last, c = ...) will no longer receive any new rows since we can no longer receive an a = a_last value due to our input data ordering. Hence, all of the partitions where a = a_last can be finalized/emitted. These observations motivate us to relax our first streamability condition into the following:
One of the
PARTITION BYexpressions should be a leading ordering expression (first expression in some existing data (input) ordering).
The table below shows some examples showing streamable and non-streamable cases.

Remark: Note that we do not have any constraint on the window frame specification in this case. Unlike the partitionless case, the window frame may end with an UNBOUNDED FOLLOWING here.
Remark: As mentioned before, directionality of data ordering doesn’t matter when assessing the PARTITION BY clause for streamability. What we care about is the ability to tell when a partition ends. In other words, it is enough to have the guarantee that when we receive a new value for the PARTITION BY expression, we will never receive any previous expression value again.
Leveraging hashing for partitioning
Even when the existing data (input) ordering doesn’t help us deal with partitions, we can still support streaming execution in certain cases by leveraging hashing. Specifically, consider the case where:
- None of the
PARTITION BYexpressions matches any leading ordering expression (the first expression in some existing data (input) ordering). - Conditions for the case when the query doesn’t contain a
PARTITION BYclause hold.
As an example, consider the window expression below:
SUM(c) OVER(
PARTITION BY c
ORDER BY ts ASC
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
)Column c is not a leading ordering column in any existing data (input) ordering, so we cannot be sure when a partition finalizes with our previous methods. What else can we do? Let’s first look at how the above expression splits our example table.
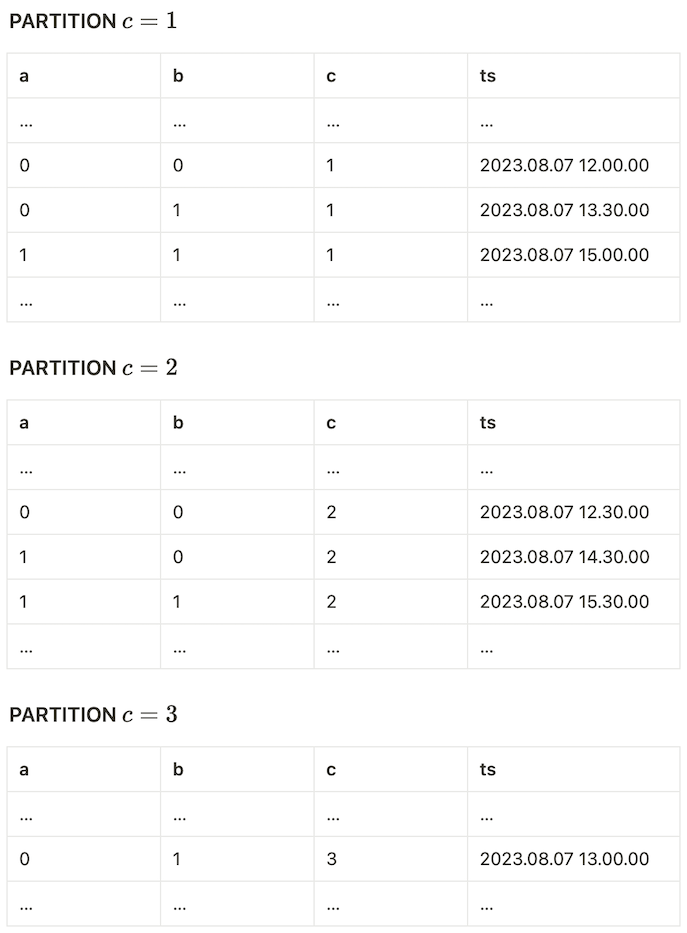
and so on.
Now, observe that the window expression reduces to the following per-partition window expression:
SUM(c) OVER(
ORDER BY ts ASC
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
)Analyzed independently, this per-partition window expression satisfies our streamability conditions. This gives us a way out:
If our conditions for the partition-less case holds for every partition separately; then we can operate on, prune and emit results for each partition concurrently as new data arrives. However, since we will never know when a partitions ends, we will have to keep track of each distinct partition throughout execution. In high cardinality cases, this version may use significant memory, but it is nevertheless pipeline-friendly.
Streamability summary
We are done with our case analysis, so let’s put together everything we have covered so far in one single statement: For a window expression to be streamable, or pipeline-friendly, we require:
- One of the
PARTITION BYexpressions to be a leading ordering expression (first expression in some existing data (input) ordering), or - The leading ordering requirement to match with an existing leading ordering and the window frame to not end with
UNBOUNDED FOLLOWING.
For the sake of clarity, we also provide a truth table encoding the above statement:

Handling Multiple Window Expressions
When a query contains multiple window expressions, the query is streamable (as a whole) if all the constituent window expressions are individually streamable. As an example, consider the query below:
SELECT
SUM(c) OVER(
ORDER BY ts ASC
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
) AS sum_last_ten_ts,
SUM(c) OVER(
ORDER BY a ASC, b ASC
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
) AS sum_last_ten_a_b
FROM sourceSince our input table (source) satisfies the requirements ts ASC and (a ASC, b ASC) simultaneously, both window expressions are streamable — they both correspond to Case 2 in the summary table above.
Next, let’s analyze a more complex example. Consider the query below:
SELECT
SUM(c) OVER(
ORDER BY ts ASC
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
) AS sum_last_ten_ts,
SUM(c) OVER(
ORDER BY ts DESC**
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
) AS reverse_sum_last_ten_ts
FROM sourceIn this query, one of the window expressions has the ordering requirement ts ASC while the other has ts DESC. At first glance, these window expressions seem to have conflicting requirements, suggesting that this query may not be streamable. When we check streamability conditions for these window expressions, the first window expression corresponds to Case 2 (streamable), but the second window expression corresponds to Case 0 (not streamable).
However, we can actually salvage this query by leveraging a simple property of window functions; i.e. most window functions are directionally insensitive. In other words, we can calculate their results even if we scan their inputs in the opposite direction (relative to their ordering requirements). In order to obtain the correct result while scanning the input in the opposite direction, we just have to modify/re-write the window frame clause. For our example, the alternate re-writing of the reverse_sum_last_ten_ts expression is:
SUM(c) OVER(
ORDER BY ts ASC
ROWS CURRENT ROW AND 10 FOLLOWING
) AS alternate_reverse_sum_last_ten_tsNote that the ordering requirement is exactly the opposite of the original ordering requirement. After this re-write, our two window expressions now have compatible requirements amenable to streaming execution, making the whole query streamable.
Constructing Equivalent Window Frames for Reverse Expressions
The section above lays out the core idea for window expression reversals, but some details were left vague. For example, what exactly does “modifying/re-writing” the window frame clause mean? We explore such details in this section.
The algorithm for constructing/re-writing equivalent window frames is actually rather simple:
- If the window frame boundary is of the form
BETWEEN M PRECEDING AND N FOLLOWING, then we swapPRECEDINGandFOLLOWINGvalues, resulting in a window frame boundary of the formBETWEEN N PRECEDING AND M FOLLOWING. - If one side of the window frame contains
CURRENT ROW, then we swap frame boundaries and reverse the other side. For instance, if the window frame boundary is of the formBETWEEN M PRECEDING AND CURRENT ROW, then the re-written window frame is of the formBETWEEN CURRENT ROW AND M FOLLOWING.
A Rust-like pseudocode implementation of this logic is as follows:
start_bound = old_window_frame.start_bound;
end_bound = old_window_frame.end_bound;
mode = old_window_frame.mode; // RANGE, ROWS, GROUPS
// Find the "reversed" start bound:
if end_bound == WindowFrameBound::Preceding(number)
rev_start_bound = WindowFrameBound::Following(number)
else if end_bound == WindowFrameBound::CurrentRow
rev_start_bound = WindowFrameBound::CurrentRow
else if end_bounde == WindowFrameBound::Following(number)
rev_start_bound = WindowFrameBound::Preceding(number)
else
Not Possible
// Find the "reversed" end bound:
if start_bound == WindowFrameBound::Preceding(number)
rev_end_bound = WindowFrameBound::Following(number)
else if start_bound == WindowFrameBound::CurrentRow
rev_end_bound = WindowFrameBound::CurrentRow
else if start_bound == WindowFrameBound::Following(number)
rev_end_bound = WindowFrameBound::Preceding(number)
else
Not Possible
// Same mode should be used:
reversed_window_frame = WindowFrame{rev_start_bound, rev_end_bound, mode}We can summarize our findings on window frame reversal as follows:
If the ordering requirement of a window expression and the existing data (input) ordering is exactly the opposite, the window expression is still streamable if streamability conditions hold for the alternate (i.e. “reversed”) version of the expression.
Remark: Certain window functions (such as FIRST_VALUE) are directionally sensitive, but are still amenable to our reversal technique. When dealing with such a “friendly” function, we simply swap the function with its dual. For instance, the following window expression
FIRST_VALUE(a) OVER(
ORDER BY ts DESC
ROWS BETWEEN 10 PRECEDING AND 1 FOLLOWING
)turns into
LAST_VALUE(a) OVER(
ORDER BY ts ASC
ROWS BETWEEN 1 PRECEDING AND 10 FOLLOWING
)when applying our reversal technique. However, most window and aggregate functions are directionally insensitive (e.g. SUM, MIN, MAX, AVG), so they remain the same as we reverse window expressions involving them.
Stateful Calculations
So far, we focused on streamability requirements without considering any memory implications. Our working definition was that an operation is streamable if we can start emitting its results without scanning its entire input. However, this may still require us to use unbounded memory, which is not feasible. As an example, window frames that start with UNBOUNDED PRECEDING may require us to store an unbounded amount of data. Consider the window expression below:
SOME_WINDOW_FUNCTION(c) OVER(
ORDER BY ts ASC
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING
)Unless we know that SOME_WINDOW_FUNCTION is amenable to incremental/stateful computation, this window expression may force us to store an ever-growing amount of data as we go through the input. The following table summarizes the rows we need to keep in memory in the worst case as we evaluate this window expression.
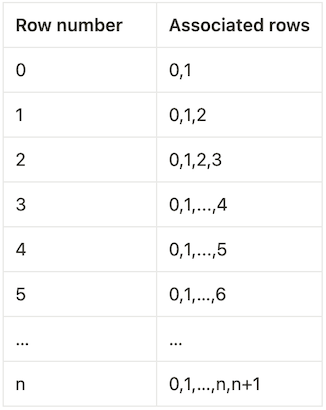
Fortunately, we can incrementally calculate/update results for most window functions without storing all the associated rows.
Consider the SUM function: We know that SUM(x,y,z,t) is equal to SUM(x,y,z) + t. In other words, we compute the sum function in an accumulating fashion: Once we compute the sum value for rows 1, 2, …, N; we no longer need to store these rows when processing the rest of our input data — all the information we will ever need will be in the accumulated value.
As another example, consider the MIN function: We know that MIN(x, y, z, t) is equal to MIN(MIN(x, y, z), t). Therefore, once we compute the minimum for rows 1, 2, …, N; we no longer need to store these rows when processing the rest of our input data. Similar algorithms can be constructed for other commonly used window functions.
However, there are “memory-unfriendly” window functions as well. Consider the ARRAY_AGG function, which constructs an array object from its input data. Even though we can emit its results without scanning the entire input, we will need to keep track of all its associated rows as we execute the query. Therefore, if a window expression involves a frame starting with UNBOUNDED PRECEDING, we will face an ever-growing (and unavoidable!) memory usage.
References and Footnotes
[1] PostgreSQL documentation: Window function processing
[2] Wikipedia article on SQL window functions.
[3] When there are multiple equivalent input orderings, it is enough for this statement to be true for one such ordering.
[4] Streaming systems by Tyler Akidau, Slava Chernyak and Reuven Lax. This is an excellent book to learn what is “under the hood” in stream processing systems. You will not just learn how to use a specific stream processing library or framework, but digest general stream processing concepts and how one can implement such libraries or frameworks. In this sense, this book will always be relevant.
[5] Efficient Processing of Window Functions in Analytical SQL Queries by Viktor Leis, Alfons Kemper, Kan Kundhikanjana and Thomas Neumann is great read for those who want to learn more about implementations of window functions.
Authors
- Mustafa Akur, Software Engineer @ Synnada
- Mehmet Ozan Kabak, CEO and Founder @ Synnada
